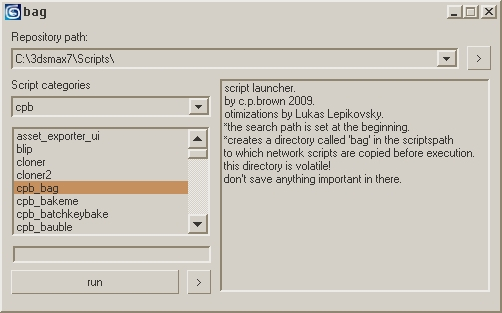
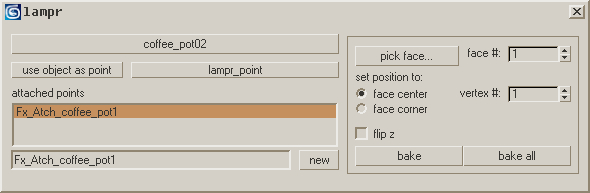
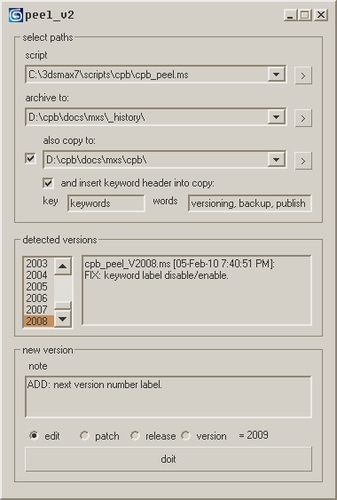
2020s
TXT
gifded:gtk4::vala:
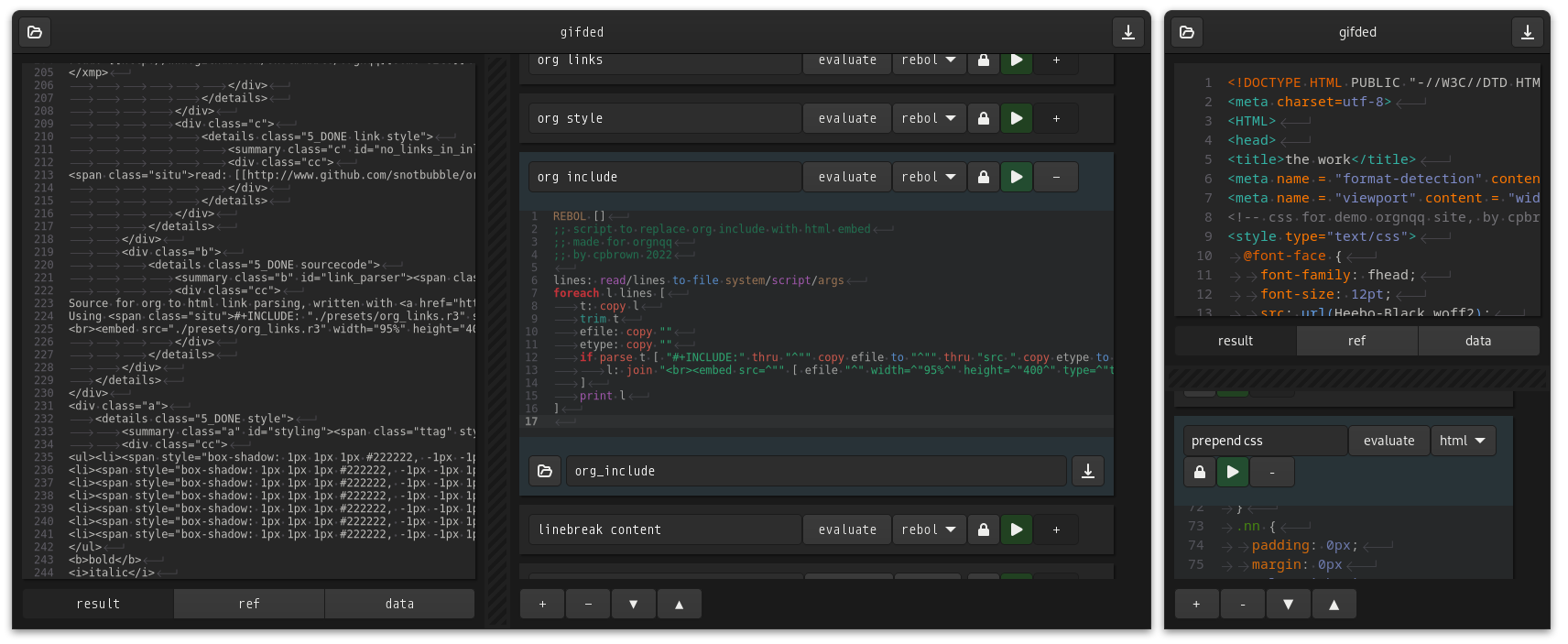
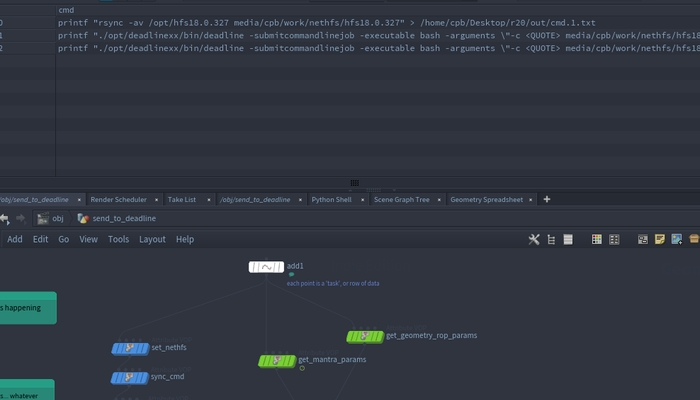
Bash together a process by mixing Python, Rebol, text or Shellscript operators... whatever works.
Used for both commercial and personal scripting projects.
This gets a lot of use, pretty happy with it.
Source is here.
Note there is no license to use this software, it exists here for my own use, should I need to obtain it via internet.
Instructions for Linux:
Currently being replaced by a node-based editor that's become a bit of a monster... so gifded is 'done'.
Used for both commercial and personal scripting projects.
This gets a lot of use, pretty happy with it.
Source is here.
Note there is no license to use this software, it exists here for my own use, should I need to obtain it via internet.
Instructions for Linux:
- extract && cd to gifded
- install vala and gtksourceview5-devel
- copy install/.local/share/gtksourceview-5 to /.local/share/
- compile using clear && valac gifded.vala --pkg gtk4 --pkg gtksourceview-5 -X -lm
- install any other dependencies it complains about, and try again
- run ./gifded
- if it looks like ass, install adw-gtk3-theme and enable via gnome-tweaks
- if it still looks like ass, SOLS: its a backward compatibility issue (being addressed in the sequel via hardcoded theme)
Currently being replaced by a node-based editor that's become a bit of a monster... so gifded is 'done'.
fulltardie:gtk4::vala::wip:
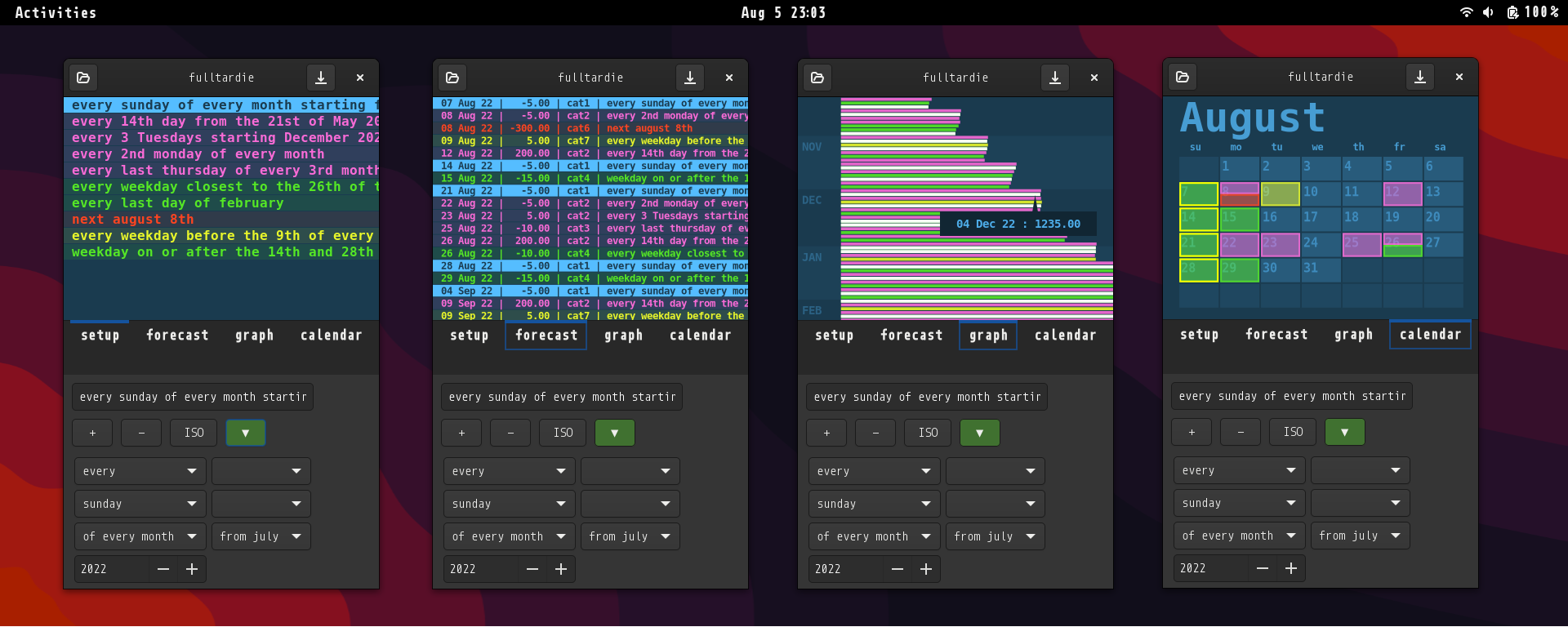
Used to keep track of a large number of recurring transactions.
Also great for quickly testing future scenarios.
This was originally a Python script written on the Blackberry to determine if I can afford overseas vfx contracts.
Briefly tried to re-write it in Swift (trap), then Red (tooslow/32-bit), then Vala/GTK3 (similar to above screenshot, useful but has QOL issues), now Vala/GTK4.
Currently being re-written to:
- Handle thousands of rules.
- Resolve various ui issues.
- Handle alternating intervals, eg: every workday on or before every 90th then 91st day from February 23rd of 2016.
- Resolve some ambiguity arising from use of plain-English to construct the rules.
- Load and save in orgmode format for easier editing.
- Undo deletion of rules.
- (maybe) add Gnome notification options.
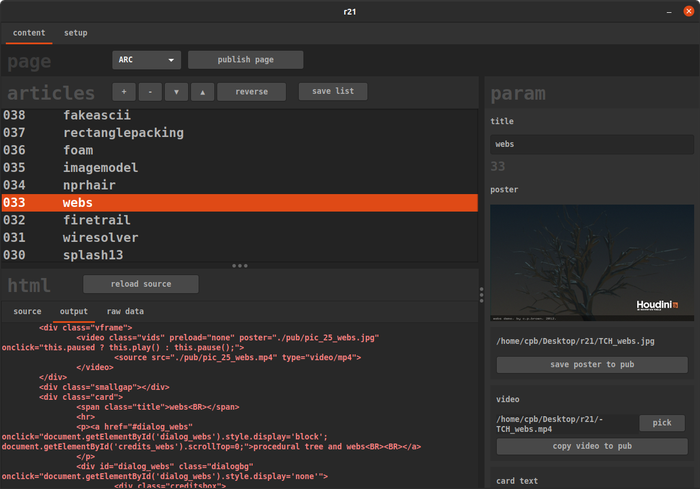
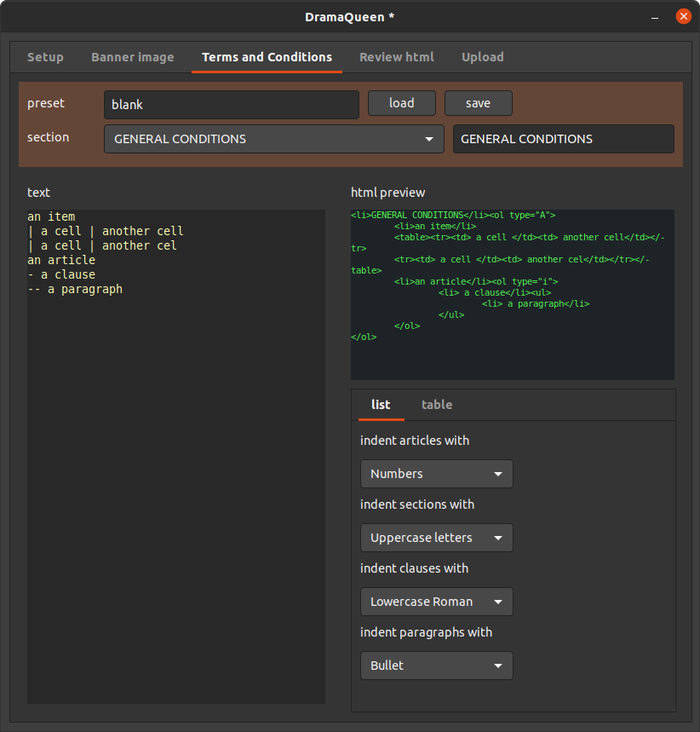
reexsa:gtk3::red:
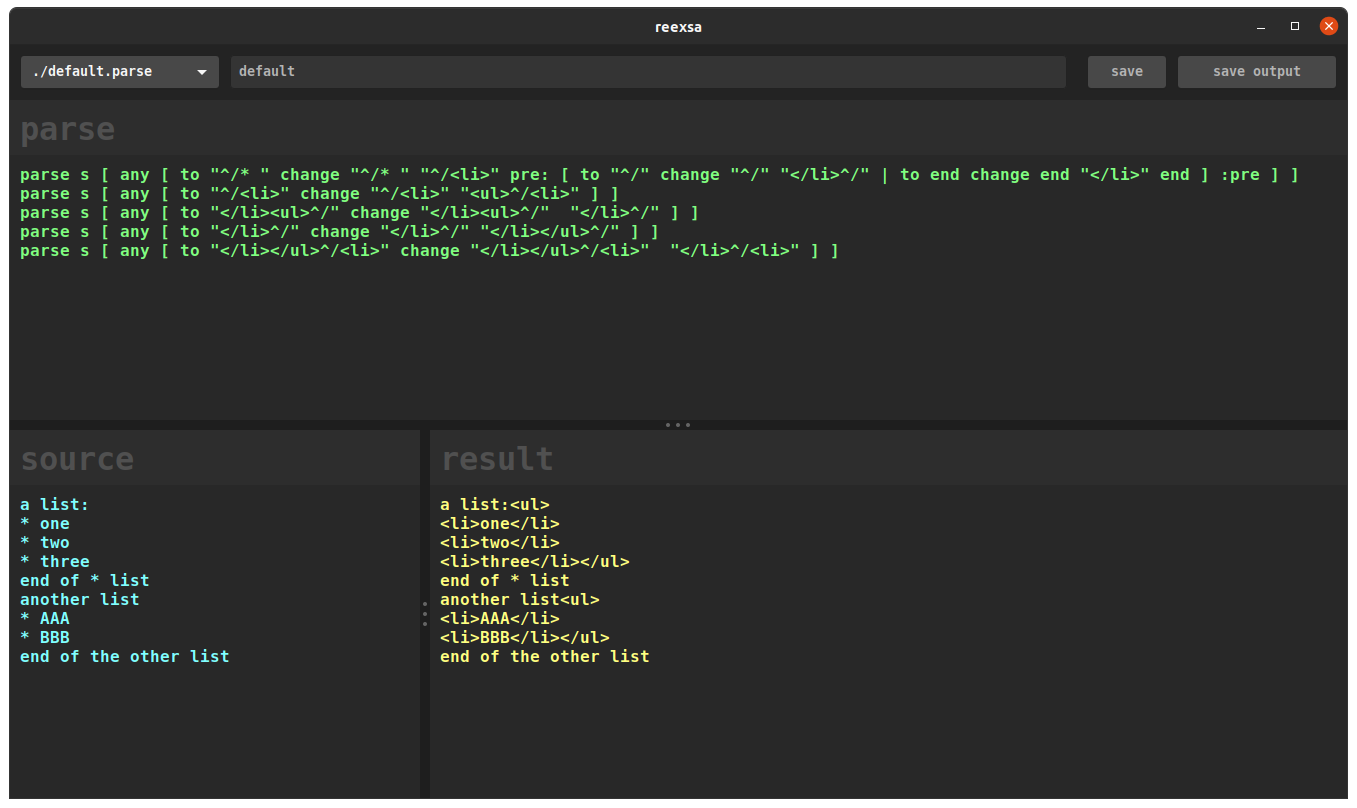
Interface for testing Red-Parse.
Red [ needs 'view ]
;; interactively test parse rules
;; by c.p.brown 2021
;;
;; attempt [] may freeze the script, uncomment if its a problem
marg: 10
tabh: 0 ;; height of the statusbar (none atm)
nudgeu: func [] [
uu/offset/x: 0
uu/offset/y: min (max 200 uu/offset/y) 600
uu/size/x: tp/size/x
vv/offset/y: uu/offset/y + 10
vv/size/y: tp/size/y - ((uu/offset/y + 10) + tabh)
maa/offset/y: 0
maa/size/x: uu/size/x
mbb/offset/y: uu/offset/y + 10
mcc/offset/y: uu/offset/y + 10
maa/size/y: uu/offset/y
mbb/size/y: vv/size/y
mcc/size/y: vv/size/y
maah/offset/y: 0
mbbh/offset/y: 0
mcch/offset/y: 0
maap/offset/y: maah/size/y + marg
mbbp/offset/y: mbbh/size/y + marg
mccp/offset/y: mcch/size/y + marg
maap/size/y: maa/size/y - (maah/size/y + (2 * marg))
mbbp/size/y: mbb/size/y - (mbbh/size/y + (2 * marg))
mccp/size/y: mcc/size/y - (mcch/size/y + (2 * marg))
uu/draw: compose/deep [
pen off
fill-pen 100.100.100
circle (to-pair compose/deep [(to-integer (uu/size/x * 0.5) - 10) 5]) 2 2
circle (to-pair compose/deep [(to-integer (uu/size/x * 0.5)) 5]) 2 2
circle (to-pair compose/deep [(to-integer (uu/size/x * 0.5) + 10) 5]) 2 2
]
]
nudgev: func [] [
vv/offset/y: uu/offset/y + 10
vv/offset/x: min (max 100 vv/offset/x) (tp/size/x - 100)
if vv/offset/x < 100 [ return 0 ]
maa/offset/x: 0
mbb/offset/x: 0
mcc/offset/x: vv/offset/x + 10
mbb/size/x: vv/offset/x
mcc/size/x: (tp/size/x - mcc/offset/x)
maah/offset/x: 0
mbbh/offset/x: 0
mcch/offset/x: 0
maah/size/x: maa/size/x
mbbh/size/x: mbb/size/x
mcch/size/x: mcc/size/x
maap/offset/x: marg
mbbp/offset/x: marg
mccp/offset/x: marg
maap/size/x: maah/size/x - (marg + marg + 1)
mbbp/size/x: mbbh/size/x - (marg + marg)
mccp/size/x: mcch/size/x - (marg + marg + 1)
vv/draw: compose/deep [
pen off
fill-pen 100.100.100
circle (to-pair compose/deep [5 (to-integer (vv/size/y * 0.5) - 10)]) 2 2
circle (to-pair compose/deep [5 (to-integer (vv/size/y * 0.5))]) 2 2
circle (to-pair compose/deep [5 (to-integer (vv/size/y * 0.5) + 10)]) 2 2
]
]
view/tight/flags/options [
title "reexsa"
below
hh: panel 800x55 35.35.35 [
parsers: drop-list 200x30 font-name "consolas" font-size 10 font-color 180.180.180 bold data (collect [foreach file read %./ [ if (find (to-string file) ".parse") [keep rejoin ["./" (to-string file)]] ]]) on-change [
pfn: copy parsers/data/(parsers/selected)
pn: ""
parse pfn [ thru "./" copy pn to ".parse" ]
parsername/text: pn
pset: load to-file parsers/data/(parsers/selected)
maap/text: (reduce pset/1)
mbbp/text: (reduce pset/2)
maap/font/color: 255.0.0 s: copy mbbp/text attempt [ do maap/text mccp/text: s maap/font/color: 128.255.128 ]
]
pad 10x0
parsername: field 200x30 font-name "consolas" font-size 10 font-color 180.180.180 bold
pnew: button 80x34 "save" font-name "consolas" font-size 10 font-color 180.180.180 bold [
if (parsername/text <> "") and (parsername/text <> none) [
newparsername: rejoin [ "./" parsername/text ".parse" ]
write to-file newparsername ( reduce [ maap/text mbbp/text ])
clear parsers/data
parsers/data: (collect [foreach file read %./ [ if (find (to-string file) ".parse") [keep rejoin ["./" (to-string file)]] ]])
parsers/selected: index? find parsers/data newparsername
]
]
pad 10x0
psave: button 160x34 "save output" font-name "consolas" font-size 10 font-color 180.180.180 bold [
if (parsername/text <> "") and (parsername/text <> none) [
op: request-dir
unless none? op [
write to-file rejoin [ op parsername "_output.txt" ] mccp/text
]
]
]
]
tp: panel 800x745 [
below
maa: panel 800x300 40.40.40 [
maah: panel 45.45.45 800x55 [
text 200x30 "parse" font-name "consolas" font-size 24 font-color 80.80.80 bold
]
maap: area 800x300 40.40.40 font-name "consolas" font-size 12 font-color 128.255.128 bold with [
text: {parse s [ any [ to "^^/* " change "^^/* " "^^/<li>" pre: [ to "^^/" change "^^/" "</li>^^/" | to end change end "</li>" end ] :pre ] ]^/parse s [ any [ to "^^/<li>" not "</li>^^/<li>" change "^^/<li>" "<ul>^^/<li>" ] ]}
] on-change [ face/font/color: 255.0.0 s: copy mbbp/text attempt [ do maap/text mccp/text: s face/font/color: 128.255.128 ] ]
]
uu: panel 800x10 30.30.30 loose [] on-drag [ nudgeu ]
across
mbb: panel 390x400 40.40.40 [
mbbh: panel 390x55 45.45.45 [
text 200x30 "source" font-name "consolas" font-size 24 font-color 80.80.80 bold
]
mbbp: area 390x300 40.40.40 font-name "consolas" font-size 12 font-color 128.255.255 bold with [
text: {a list:^/* one^/* two^/* three^/end of * list^/another list^/* AAA^/* BBB^/end of the other list} ;;*/ <- emacs red-mode is screwy atm
] on-change [ face/font/color: 255.0.0 s: copy mbbp/text attempt [ do maap/text mccp/text: s face/font/color: 128.255.128 ] ]
]
vv: panel 10x390 30.30.30 loose [] on-drag [ nudgev ]
mcc: panel 390x400 40.40.40 [
mcch: panel 390x55 45.45.45 [
text 200x30 "result" font-name "consolas" font-size 24 font-color 80.80.80 bold
]
mccp: area 390x345 40.40.40 font-name "consolas" font-size 12 font-color 255.255.128 bold
]
]
do [
if exists? %./default.parse [
pset: load %./default.parse
maap/text: (reduce pset/1)
mbbp/text: (reduce pset/2)
parsername/text: "default"
parsers/selected: index? find parsers/data "./default.parse"
maap/font/color: 255.0.0 s: copy mbbp/text attempt [ do maap/text mccp/text: s maap/font/color: 128.255.128 ]
]
psave/offset/x: tp/size/x - (psave/size/x + marg)
pnew/offset/x: psave/offset/x - (pnew/size/x + marg)
parsername/offset/x: (parsers/offset/x + parsers/size/x + marg)
parsername/size/x: pnew/offset/x - (parsers/size/x + (4 * marg))
nudgeu nudgev
]
] [ resize ] [
actors: object [
on-resizing: function [ face event ] [
if face/size/x > 500 [
if face/size/y > (uu/offset/y + 200) [
hh/size/x: face/size/x
tp/size: face/size - 0x55
psave/offset/x: face/size/x - (psave/size/x + marg)
pnew/offset/x: psave/offset/x - (pnew/size/x + marg)
parsername/offset/x: (parsers/offset/x + parsers/size/x + marg)
parsername/size/x: pnew/offset/x - (parsers/size/x + (4 * marg))
nudgeu nudgev
]
]
]
]
]
REF
VALA TESTS:vala:
Attempt to solve the riddle of:
1DARRAYS:vala:
Use a 1d array + colcount for 2d data, as a workaround for non resizable native 2d arrays.
pros: can resize in situ; no need to duplicate data
cons: extra work
string printstringrowcol (int c, string[] s) {
string o = "{ ";
for (int i = 0; i < (s.length - 1); i++) {
o = (o + s[i]);
if (((i+1) % c) == 0) { o = o + "\n "; } else { o = o + ";"; }
}
o = (o + s[(s.length - 1)] + " }\n");
return o;
}
void main() {
string[] s = { "0", "1", "2", "3", "1", "A", "B", "C", "2", "X", "Y", "Z" };
// col 0 1 2 3 0 1 2 3 0 1 2 3
// row 0 0 0 0 1 1 1 1 2 2 2 2
// index 0 1 2 3 4 5 6 7 8 9 10 11
int colcount = 4; // note: count, not index
int rowcount = (s.length / colcount);
print("s is \n%s",printstringrowcol(colcount,s));
int row = 0;
int col = 3;
int idx = (col+(row*colcount));
print("index of row[%d] and col[%d] is %d \"%s\"\n",row,col,idx,s[idx]);
// get row and column from index
idx = 3;
row = idx / colcount;
col = idx % colcount;
print("(row,col) at index %d is (%d,%d)\n",idx,row,col);
// remove col 1
col = 1;
int lastcol = colcount - 1;
int n = 0;
for (int i = col; i < (s.length - rowcount); i++) {
if (((i-col) % lastcol) == 0) { n += 1; }
s[i] = s[i+n];
}
s.resize(s.length - rowcount);
colcount -= 1;
print("s without col[%d] is \n%s",1,printstringrowcol(colcount,s));
// get index from row and column
row = 2;
col = 1;
idx = (col+(row*colcount));
print("index of row[%d] and col[%d] is %d \"%s\"\n",row,col,idx,s[idx]);
row = idx / colcount;
col = idx % colcount;
print("(row,col) at index %d is (%d,%d)\n",idx,row,col);
// test
int[] ia = {0, 1, 2, 3, 4, 5};
ia = ia + 1;
foreach (int i in ia) { print("%d\n",i); }
}
#+RESULTS:
s is
{ 0;1;2;3
1;A;B;C
2;X;Y;Z }
index of row[0] and col[3] is 3 "3"
(row,col) at index 3 is (0,3)
s without col[1] is
{ 0;2;3
1;B;C
2;Y;Z }
index of row[2] and col[1] is 7 "Y"
(row,col) at index 7 is (2,1)
0
1
2
3
4
5
1
- row at index is (index / colcount)
- col at index is (index % colcount)
- index at (row,col) is ((row * colcount) + col)
- rowcount is (length / colcount)
pros: can resize in situ; no need to duplicate data
cons: extra work
#+RESULTS:
BIASGAIN:vala:
Biasgain test
Based on the work of Christophe Schlick : https:dept-info.labri.fr/~schlick/DOC/gem2.html
#+RESULTS:
BITWISE:vala:
Misc bitwise tests.
#+RESULTS:
CAIROSCRIPT:busted::wip::vala:
Render Cairo from text commands at runtime.
Pan & zoom is currently busted.
CASE:vala:
String cleanup for searching.
string.down() & string.up() return copies of string.
In-place _.strip() spews a bunch of warnings, but the resulting string is valid.
#+RESULTS:
CHARCOUNT:vala:
#+RESULTS:
COLCTRL:vala:
#+RESULTS:
[2_FIX.]COLLATE:vala:
Collate test.
#+RESULTS:
COLRESIZE:vala:
#+RESULTS:
COLUMNID:vala:
#+RESULTS:
COMPACT:vala:
Reduce multiple contiguous whitespaces to one single space.
Considers newline a whitespace.
#+RESULTS:
CONCAT:vala:
#+RESULTS:
CONDITIONAL:vala:
#+RESULTS:
CONTAINERSWITHINCONTAINERS:vala:
#+RESULTS:
CONTIGUOUS:vala:
#+RESULTS:
DATE2:wip::vala:
second attempt at a generic setdate()
Better provision for correction in a date sequence.
Still contains errors, this will be replaced at some point.
#+RESULTS:
DAYCOUNT:wip::vala:
Count nth days per month.
Takes a month list, from-day per month, nth-day from from-day.
Can span years.
Handles leap-years correctly.
Ignores invalid input.
Options:
- from-day + nth-day
- from-day + nth-weekday
- from-day + nth-workday-on-or-before-day
- from-day + nth-workday-on-or-after-day
- from-day + nth-workday-closest-to-day
#+RESULTS:
DSVALIGN:vala:
Align columns of a dsv string to acommodate their content.
#+RESULTS:
DUHWADE:vala:
Get parent of relative path
#+RESULTS:
FAKESCROLL:vala:
Math for fake scrolling data where there's a variable number of lines per row.
Has to work with scaling.
Inputs are:
- line height (scaled)
- list of lines
- list of rows
- list of row indices per line
- list of lines per row
- position offset (from user, eg scroll offset)
This extends linesperrow below
#+RESULTS:
FILEBYIDX:wip::vala:
Re-arrange a string array using an int array of indices.
Requres more testing for edge cases...
#+RESULTS:
FILESEEK:io::vala:
Read a file as 100-char lines
Use of StringBuilder.append((string) buf) was found to prevent both buffer overflow and incorrect rendering of unicode.
#+RESULTS:
FILESTREAM:io::vala:
Load a large file line by line. Avoid overflow using StringBuilder.
Use persistent storage class(es) instead of string[] for anything more involved than run'n'done programs.
#+RESULTS:
FOLD:vala:
tokenize_and_fold vs string._delimit & split...
_delimit pros
_delimit cons
// tokenize_and_fold vs _delimit & split
// by c.p.brown 2024
void main() {
string[] o;
string s = "1,2;3\"45\"\n6-78\'AB.C_DE(F)$GH{I\nJK}AB101";
int64 tts = GLib.get_monotonic_time();
string[] tkn = s.tokenize_and_fold("en_US",out o);
int64 ttl = GLib.get_monotonic_time();
print("string.tokenize_and_fold is {\n");
for (int i = 0; i < tkn.length; i++) { print("\"" + tkn[i] + "\"\n"); }
print("}\n");
print("tokenize_and_fold took %.2f microseconds\n\n",((double) (ttl - tts)));
string q = "1,2;3\"45\"\n6-78\'AB.C_DE(F)$GH{I\nJK}AB101";
string d = ",;\"\';._-$(){}\n";
char npdc = '\x1F';
string npd = "%c".printf(npdc);
tts = GLib.get_monotonic_time();
q._delimit(d,npdc);
string[] w = q.split(npd);
int[] rr = {};
for (int i = 0; i < w.length; i++) {
if ((w[i] == null) || (w[i].strip() == "") || (w[i].strip() == "\n")) {
rr += i;
}
}
if (rr.length > 1) {
int[] gaps = {693731, 270033, 133481, 7106, 3121, 1303, 701, 301, 132, 57, 23, 10, 4, 1};
int n = rr.length;
foreach (int g in gaps) {
for (int i = 0; i < n; i++) {
int t = rr[i];
int j = i;
if (j >= g) {
bool c = (rr[j - g] < t);
while (c) {
rr[j] = rr[j - g];
j -= g;
if (j < g) { break; }
c = (rr[j - g] < t);
}
}
rr[j] = t;
}
}
n = 0;
int a = rr[rr.length - 1];
int j = rr.length;
int f = 0;
for (int i = a; i < (w.length - j); i++) {
int b = (i + f);
while (b in rr) {
f += 1;
b += 1;
rr.resize(rr.length - 1);
}
w[i] = w[i + f];
}
w.resize(w.length - j);
} else {
if (rr.length == 1) {
for (int i = rr[0]; i < w.length; i++) {
if ((i + 1) < w.length) {
w[i] = w[i + 1];
}
}
w.resize(w.length - 1);
}
}
ttl = GLib.get_monotonic_time();
print("string._delimit and split is {\n");
for (int i = 0; i < w.length; i++) { print("\"" + w[i] + "\"\n"); }
print("}\n");
print("_delimit and split took %.2f microseconds\n\n",((double) (ttl - tts)));
}
#+RESULTS:
string.tokenize_and_fold is {
"1"
"2"
"3"
"45"
"6"
"78"
"ab"
"c"
"de"
"f"
"gh"
"i"
"jk"
"ab101"
}
tokenize_and_fold took 16.00 microseconds
string._delimit and split is {
"1"
"2"
"3"
"45"
"6"
"78"
"AB"
"C"
"DE"
"F"
"GH"
"I"
"JK"
"AB101"
}
_delimit and split took 5.00 microseconds
_delimit pros
- much faster, even with cleanup
- preserves case
- can choose exactly what to use as delimiters
_delimit cons
- won't work with multi-character delimiters - as with tokenize, to be fair
- will insert sequential delimiters, resulting in empty array items when split
- adds an extra empty array item at the end if the last char is a delimiter
- removing empties requires onerous cleanup work & testing,
- or handling emties every time the array is accessed
#+RESULTS:
FONTMATRIX:cairo::gtk4::vala:
Smooth scaling of fonts.
Disable hinting to prevent jank when interactively resizing text.
Avoid cumulative scaling by writing directly to fontmatrix.xx and fontmatrix.yy, instead of fontmatrix.scale()
FONTRESOURCE:busted::vala:
ugh I just want to load a font and have widgets use it...
FORECAST:wip::vala:
Complex recurrence, revisited.
This revision intends to cover the following scenarios not handled previously:
- Every nth day (or weekday) of a single month.
- Every nth and nth day in alternation, either per-month or absolute, eg:
- The 2nd and 3rd day of March (2,3).
- The 2nd and 3rd day of March, from the 5th (7,8).
- Every 2nd then 3rd day of March (2,5,7,10,12,15,17,20,22,25,27,30).
- Every 2nd then 5th day of March, from the 10th (12,17,19,24,26).
- The 2nd and 3rd Tuesday of March 2025 (11,18).
- The 2nd and 3rd Tuesday of April 2025, from the 12th (22,29).
- Every 2nd then 3rd Tuesday of April 2025 (8,29).
- Every 90 and 91 days from July 1st 2025.
- Every nth and nth month in alternation, eg:
- The 2nd and 10th month of every year (2,10).
- The 2nd and 5th month, from the 2nd month, of every year (4,7).
- Every 2nd then 3rd month of every year (2,5,7,10,12).
- Every 2nd then 3rd month, from the 3rd month, of every year (5,8,10).
- Every 4th month from March 2025.
- Every nth year.
#+RESULTS:
GETCHAR:vala:
Getting indices of unichar characters:
for (int x = 0; x < s.char_count(); x++) { ch = s.get_char(s.index_of_nth_char(x)); }
#+RESULTS:
tests:
#+RESULTS:
GETCHARPACKET:vala:
#+RESULTS:
GETDUPES:vala:
Get rows of duplicate data in a column, using an array of row indices.
Used for re-sorting rows of data by column where the initial sort returns contiguous sequences of same-values, eg:
Unsorted data:
| I | DATA[] | |---+--------| | 0 | "CC" | | 1 | "AA" | | 2 | "EE" | | 3 | "DD" | | 4 | "DD" |
Sorted as indices (X) of DATA:
| I | DATA[] | X[] | DATA[X[I]] | |---+--------+-----+------------| | 0 | "CC" | 1 | (AA) | | 1 | "AA" | 0 | (CC) | | 2 | "EE" | 3 | (DD) | | 3 | "DD" | 4 | (DD) | | 4 | "DD" | 2 | (EE) |
Contigious ranges of duplicates in DATA[X[I]]:
| I | DUPES[] | DATA[(((DUPES[I]>>32)*COLCOUNT)+COL)] | |---+---------+---------------------------------------| | 0 | 2..3 | "DD" |
#+RESULTS:
GETFILEPARTS:vala:
#+RESULTS:
GTKMENU:vala:
custom gtk menu
GESTUREDRAG:gtk4::vala:
test gesture events...
// test gtk events in a bare-minimum application
// by c.p.brown 2023
using Gtk;
int main (string[] args) {
Gtk.Application wut = new Gtk.Application ("com.test.test", GLib.ApplicationFlags.FLAGS_NONE);
wut.activate.connect(() => {
double[] mdn = {0.0,0.0};
double[] moo = {0.0,0.0};
double[] mof = {0.0,0.0};
Gtk.ApplicationWindow win = new Gtk.ApplicationWindow(wut);
Gtk.DrawingArea im = new Gtk.DrawingArea();
im.margin_top = 10;
im.margin_bottom = 10;
im.margin_start = 10;
im.margin_end = 10;
Gtk.GestureDrag gd = new Gtk.GestureDrag();
im.add_controller(gd);
im.set_draw_func((da,ctx,daw,dah) => {
var bc = Gdk.RGBA();
bc.parse("#112633");
ctx.set_source_rgba(bc.red,bc.green,bc.blue,1);
ctx.paint();
bc.parse("#DDDD88DD");
ctx.set_source_rgba(bc.red,bc.green,bc.blue,bc.alpha);
ctx.set_line_width(2.0);
ctx.move_to(mof[0],0.0);
ctx.line_to(mof[0],dah);
ctx.stroke();
ctx.move_to(0.0,mof[1]);
ctx.line_to(daw,mof[1]);
ctx.stroke();
string inf = "x = %0.2f, y = %0.2f".printf(moo[0],moo[1]);
ctx.select_font_face("Monospace",Cairo.FontSlant.NORMAL,Cairo.FontWeight.BOLD);
Cairo.TextExtents extents;
ctx.text_extents (inf, out extents);
ctx.set_source_rgba(((float) 0.9),((float) 0.9),((float) 0.4),((float) 0.9));
ctx.move_to(20.0,(dah - extents.height));
ctx.show_text(inf);
});
gd.drag_begin.connect((event,x,y) => {
print("device button is %u\n", event.get_current_button());
mdn = {x,y};
});
gd.drag_update.connect((event,x,y) => {
moo = {x,y};
mof = {mdn[0] + x,mdn[1] + y};
im.queue_draw();
});
win.default_width = 300;
win.default_height = 300;
win.set_child(im);
win.present();
});
return wut.run(args);
}
#+RESULTS:
#+RESULTS:
GOLDPACT:vala:
Check char pair balance.
Used to validate expressions before parsing them.
#+RESULTS:
HEX:vala:
Convert uint to and from hexadecimal strings.
Add trailing zeroes where required, this is more of a printf() problem as it hoses zeroes.
The question is: pre-pad the hex string before uint, or post-pad when converting uint to string? The latter requires a persistent character-count variable, but doesn't mess with the data.
#+RESULTS:
INHERIT:vala:
In Vala simply writing an Object inside another Object won't allow it to access stuff in the outer Object as they're two distinct Objects. Technically both Objects should be written separately and the 'parent' Object, or a subset of its properties, is passed as args to the 'child' Object, or in Gtk use parentobject myparent (parentobject) = this.get_ancestor(typeof(parentobject)); where the UI Objects are nested. An example of get_ancestor() can be seen in GTKMENU where a clicked menu-item changes other menu-items in its parent container, and also a label in a 'parameters' Object to which the menu-button belongs.
INTERLEAVE:vala:
Combine and sort two index arrays of a string array.
Used to combine segments of a multithreaded sort.
#+RESULTS:
ISDIGIT:vala:
Text to numbers
#+RESULTS:
[1_IP..]ISCONTAINEDBY:wip::hash::vala:
Dedupe an address list.
Check if another data source addresses are all within deduped list.
Allow masked dedupe using a rowmask.
This test consumes approx 203mb of memory according to /usr/bin/time -f "%M" ./valatemp
Test records sourced from: https://www.dol.gov/agencies/eta/foreign-labor/performance
Column labeling logic is derivative work of various other derivative works, primary source unknown.
#+RESULTS:
INGLICNUMS_GFN:vala:
Convert numbers to its English description.
Obsolete, needs rewrite for multithreading.
#+RESULTS:
JOINV:vala:
#+RESULTS:
LINESPERROW:vala:
Get a row offset given n lines per row, h height per line, y view hieght, o scroll offset...
#+RESULTS:
LOADORGARTICLE:vala:
Load a top-level article from an org file.
(Double semi-colons inserted into results here to prevent orgception, which is not fun)
#+RESULTS:
LOOKAHEAD:vala:
Lookahead for an un-quoted, un-escaped character.
#+RESULTS:
MEDIAN:vala:
#+RESULTS:
MASKARRAY:wip::vala:
Mask arrays using various mask types.
Layer masks using a selectionset object, with its own getter/setter functions.
#+RESULTS:
MODULO:vala:
Misc modulo sanity-checks go here...
#+RESULTS:
NESTEDLOGIC:vala:
Group items of a comparison list using an indent value, to emulate things like:
true AND true OR (false OR true) AND true
#+RESULTS:
NTHROW:vala:
Check math for row nth + offset in a 1D array.
Used to reduce iteration in certian cases.
#+RESULTS:
OOPVSNATIVE:thread::vala:
Test to determine costs of abstraction when writing to int[] arrays.
#+RESULTS:
PACKETS:vala:
Get lists of ints in range by nth + offset, using max list size
Useful for threading x items over y threads.
Nth & offset useful for skipping items, like quoted parts of strings for example:
#+RESULTS:
PACKETLITE:vala:
Break seqential range into n packets, return in/out indices only.
#+RESULTS:
PLUGINS:vala:
Aka Modules...
Don't. Its the path to labyrinthine dependency-hell. Just use a editor that can list the code structure in a side panel for faster navigation.
PRINT1DARRAY:vala:
Assumes array is an unrolled 2d string[]
#+RESULTS:
PRINT2DARRAY:vala:
#+RESULTS:
PRINTF:vala:
#+RESULTS:
RANDOCHAR:rand::vala:
xorshift vs GLib.Rand()
Based on Xorshift RNGs (2003) by George Marsaglia.
xorshift is many times faster than GLib.Rand(), however there's some noticeable repetition.
Results are also highly sensitive to the number provided as a seed (to offset), where a set of offsets that works with 1+i may fail to produce pseudo-random results with 1000000+i.
#+RESULTS:
READLINE:vala:
Read a particular line from a huge file.
Pre-index the lines to allow multithreading.
Requested line number is 1-based.
#+RESULTS:
REDBUTTON:vala:
A button with a signal that changes its color
Try to make this code as simple as possible without golfing.
GTK OOP is great for complex interfaces, onerous for simple ones, and thus a massive hurdle for new users, especially those who were spoiled with things like:
REPLACECHAR:vala:
Test 3 methods of removing a char:
- StringBuilder.replace() : approx 5 microseconds
- manual incramental index_of() & substring() : approx 10 microseconds
- default string.replace() : approx 35 micorseconds
Not sure how stringBuilder is faster, my guess is its doing in-place char-array shuffling/resizing, while the manual method makes new substrings, then uses them to rebuild the string.
The default replace may be restarting from the beginning of the string after each replace.
Update this later with an attempt at manually manipulating a unichar array.
#+RESULTS:
REPLACEUNQUOTED:thread::vala:
Replace text if it isn't quoted.
Includes a bonus attempt at sampling to determine if its worth multithreading, since using ThreadPool can be slower in some cases. Interestingly the average sample time was closest to actual, at 16 tasks 16 threads, as opposed to max and median. Also the difference between sample times can be used to determine the task:thread ratio, where consistently even times can be sent at 1:1, high variance should go at 2:1 or more. There is a point of diminishing returns, but not sure how to determine it. In this case doubling the task count cut the total time by at least 5x.
#+RESULTS:
RESIZE:vala:
Check array resizing.
- resizing a fixed-length array results in an overflow warning
- resizing a variable-length array does not
The overflow warning was:
‘memset’ specified size 18446744073709551568 exceeds maximum object size 9223372036854775807 [-Wstringop-overflow=]
Fixed length array stresstest was also approx 10% slower than the variable array.
#+RESULTS:
ROWCTRL:vala:
Misc row manipulation functions
#+RESULTS:
RUNNINGTOTAL:vala:
#+RESULTS:
SCRAPE:busted::vala:
Get rendered text of a html/java document.
Uses webkit, which has to display in a ui before it will do anything else.
There might be a workaround, need more testing.
#+RESULTS:
SEARCH:vala:
REPLACEVSSPLIT:vala:
Test (ab)use of stringbuilder.replace vs string.split for finding substrings.
Result: same for small strings, StringBuilder many times faster for large strings, presumably because it isn't creating a string array.
#+RESULTS:
STRINGINSTRING:vala:
Return line numbers of lines of text that contain a string.
Target time is < 500ms for 1m lines in leipzig1M.txt
#+RESULTS:
SETCSS:vala:
SETPROPERTY:vala:
#+RESULTS:
SORT:vala:
ASCIISORT:busted::vala:
This is an early precursor of the tests below, will be removed once I strip it for useful parts.
#+RESULTS:
MT STRING BUCKET SORT:thread::vala:
Multitasking string bucket sort.
- Only sorts row indices, not the string[] itself.
- Slightly faster than the single-threaded quicksort for 1M strings, however this technique should pull-ahead with larger arrays.
- English-only: Partitioning using the ASCII table won't be useful for unicode characters.
- Doesn't handle 'numbers' as one would expect, eg 1000 is less than 2.
- No option to ignore case.
- Won't work with masked (non-contigious) indices, eg: lines 43001271,30015860,6302,7042, etc.
- For unicode, an additional step (transliteration) would be required to determine closest ASCII pronounciation, eg: ZH-HK '零' going to bucket 108 ('l'). Readable transliteration-byte(s) is not a feature of unicode.
#+RESULTS:
QUICKSORT:vala:
Quicksort string indices.
Function shoved into an object in case it needs to be used with ThreadPool.
Switches to shellsort when the sub-range length is below 101.
#+RESULTS:
SCRAMBLE:rand::vala:
Uses shellsort to do random swaps.
Uses xorshift by George Marsaglia.
Shellsort gap ranges by Ying Wai Lee.
#+RESULTS:
SHELLSORT:vala:
Another shellsort test.
This is derivative work, from various sources including Wikipedia & Rosetta Code.
Gap sequence by Marcin Ciura
shellsort
Limited to 9 numbers, useful for short arrays as it can just be hardcoded.
| n | gap | ng | plot | |---+------+--------+----------------------------------------------------| | 9 | 1750 | 1.0000 | ██████████████████████████████████████████████████ | | 8 | 701 | 0.4006 | ████████████████████ | | 7 | 301 | 0.1720 | █████████ | | 6 | 132 | 0.0754 | ████ | | 5 | 57 | 0.0326 | ██ | | 4 | 23 | 0.0131 | █ | | 3 | 10 | 0.0057 | █ | | 2 | 4 | 0.0023 | | | 1 | 1 | 0.0006 | | |---+------+--------+----------------------------------------------------| #+TBLFM: $3=($2/1750.0);%.4f :: $4='(orgtbl-uc-draw-cont $2 1.0 1750.0 50)
Long gap sequence by Ying Wai Lee
Empirically Improved Tokuda Gap Sequence in Shellsort
| n | gap | ng | plot | |---+------+--------+----------------------------------------------------| | 9 | 1158 | 1.0000 | ██████████████████████████████████████████████████ | | 8 | 516 | 0.4456 | ███████████████████████ | | 7 | 230 | 0.1986 | ██████████ | | 6 | 102 | 0.0881 | █████ | | 5 | 45 | 0.0389 | ██ | | 4 | 20 | 0.0173 | █ | | 3 | 9 | 0.0078 | █ | | 2 | 4 | 0.0035 | █ | | 1 | 1 | 0.0009 | | |---+------+--------+----------------------------------------------------| #+TBLFM: $2=(floor((pow(2.243609061420001,$1)/(2.243609061420001 - 1.0)))) :: $3=($2/@2$2);%.4f :: $4='(orgtbl-uc-draw-cont $2 1.0 1158.0 50)
xorshift pseudorandom number technique by George Marsaglia
Xorshift RNGs
#+RESULTS:
SORT STRING NUMBERS:rand::vala:
Test to clean-up string numbers and sort them as if they were numbers.
Doesn't humor fucky Leibniz notation, but otherwise should tolerate unicode.
#+RESULTS:
SPLIT:vala:
NOTE: split may return empty strings when the delimiter is at either end of the string
string ";1;2;3;4;5;
split ^|^|^|^|^|^
|;|;|;|;|;|;|
|?|1|2|3|4|5|?|
partitions |1|2|3|4|5|6|7|
void main(string[] args) {
string s = "| 1 | 2 | 3 | 4 | 5 |";
string[] p = s.split("|");
print("last item : %s\n",p[p.length - 1]);
print("p.length = %d\n",p.length);
}
#+RESULTS:
last item :
p.length = 7
#+RESULTS:
SPLITUNQUOTED:wip::vala:
Split strings like "A,B,C,"123\\"4,5",D,E,"F"
#+RESULTS:
STRINGBUILDER:vala:
StringBuilder tests
Notes:
- erase(x,y) is from-and-including x, to-and-including x+y
- erase(x,-1) doesn't work with unicode
#+RESULTS:
STRFTIME:vala:
DateTime
- has time and timezone
- can get components as integers, but can't set them - at all
- has no strftime()
- has no valid()
- has add, but not subtract
Date
- can set components as integers, but can't get them as integers
- has no time
- has add and subtract
- has strftime, but is requires a char array
DateTime is a beter storage format, as it can include time & timezone, but Date is easier to manipulate & display
#+RESULTS:
SUBCLASS:wip::vala:
#+RESULTS:
SUBSTRING:vala:
Note: ASCII only.
substring(x,y), where x is from and including, y is to and excluding (x+y)-1, eg:
substring(1,2) of "012345" is
1+2 is 3, -1 is 2 ||
"12"
substring(4,2) of "012345" is
4+2 is 6, -1 is 5 ||
"45"
substring(0,2) of "012345" is
0+2 is 2, -1 is 1 ||
"01"
substring(x,(y-x)), where x is from and including, y is to and excluding, eg:
substring(1,(4-1)) of "012345" is
"123"
substring(3,(5-3)) of "012345" is
"34"
substring(x,((y-x)+1)), where x is from and including, y is to and including, eg:
substring(1,((4-1)+1)) of "012345" is
"1234"
substring(3,((5-3)+1)) of "012345" is
"345"
To get first/last n characters:
void main (string[] args) {
string s = "file.ext";
int ii = s.last_index_of(".");
print("file part .....: %s\n",s.substring(0,ii));
print("extension part : %s\n",s.substring(ii));
}
#+RESULTS:
file part .....: file
extension part : .ext
to get from-and-including 2 to-and-including 5 from "0123456789"
start....... 2 ( 01[23456789 )
12^
end......... 5+1 ( 01[234567]89 )
12 123456^
end (5+1)-start ( 01[2345]6789 )
12 1234^
int s = 2;
int e = 5;
substring(s,((e+1)-s));
substring(2,6) = "234567"
substring(2,(6-2)) = "2345"
void main (string[] args) {
string s = "012345";
string t = "ABCDE";
string u = "((AA + (BB / CC)) * EE)";
print("\"%s\".substring(1,2) is %s\n",s,s.substring(1,2));
print("\"%s\".substring(4,2) is %s\n",s,s.substring(4,2));
print("\"%s\".substring(1,(4-1)) is %s\n",s,s.substring(1,(4-1)));
print("\"%s\".substring(3,(5-3)) is %s\n",s,s.substring(3,(5-3)));
print("\"%s\".substring(1,((4-1)+1)) is %s\n",s,s.substring(1,((4-1)+1)));
print("\"%s\".substring(3,((5-3)+1)) is %s\n",s,s.substring(3,((5-3)+1)));
print("\"%s\".substring(2) is %s\n",s,s.substring(2));
print("\"%s\".substring(0,100) is %s\n",s,s.substring(0,100));
print("\"%s\".substring(0,s.char_count()) is %s\n",s,s.substring(0,s.char_count()));
print("\"%s\".substring(2,(2-2)) is %s\n",s,s.substring(2,(2-2)));
int ii = u.last_index_of("(");
string m = u.substring(ii);
int oo = m.index_of(")") + 1;
print("inner expression of %s is %s\n",u,u.substring(ii,oo));
}
#+RESULTS:
Compilation succeeded - 1 warning(s)
"012345".substring(1,2) is 12
"012345".substring(4,2) is 45
"012345".substring(1,(4-1)) is 123
"012345".substring(3,(5-3)) is 34
"012345".substring(1,((4-1)+1)) is 1234
"012345".substring(3,((5-3)+1)) is 345
"012345".substring(2) is 2345
"012345".substring(0,100) is (null)
"012345".substring(0,s.char_count()) is 012345
"012345".substring(2,(2-2)) is
inner expression of ((AA + (BB / CC)) * EE) is (BB / CC)
Practical usage: extract a link from a paragraph
void main (string[] args) {
string p = "some paragraph\nwith a [[val:variable]] link in it\nand [[val:another]], just to be difficult";
string c = p;
string[] l = {};
int s = 0;
while (c.contains("[[val:") && c.contains("]]")) {
int ii = c.index_of("[[val:");
int oo = c.index_of("]]") + 2;
//print("ii = %d, oo = %d\n",ii,oo);
if (oo > ii) {
string e = c.substring(ii,(oo - ii));
//print("\tfound link: (%s)\n",e);
if (e != "") {
l += e.replace("]]","").split(":")[1];
c = c.replace(e,"");
//print("c = %s\n",c);
}
}
s += 1;
if (s > 10) { break; }
}
print("original paragraph:\n\t%s\n\n",p.replace("\n","\n\t"));
print("leftover paragraph:\n\t%s\n\n",c.replace("\n","\n\t"));
print("harvested linked vars:\n");
foreach (string k in l) { print("\t%s\n",k); }
}
#+RESULTS:
original paragraph:
some paragraph
with a [[val:variable]] link in it
and [[val:another]], just to be difficult
leftover paragraph:
some paragraph
with a link in it
and , just to be difficult
harvested linked vars:
variable
another
substring(x,y), where x is from and including, y is to and excluding (x+y)-1, eg:
substring(x,(y-x)), where x is from and including, y is to and excluding, eg:
substring(x,((y-x)+1)), where x is from and including, y is to and including, eg:
To get first/last n characters:
#+RESULTS:
to get from-and-including 2 to-and-including 5 from "0123456789"
substring(2,(6-2)) = "2345"
#+RESULTS:
Practical usage: extract a link from a paragraph
#+RESULTS:
TAKEROWS:vala:
#+RESULTS:
THREADS:busted::vala:
Observations on using Threadpool:
- Both of these methods of accessing data seem fine: worker.run(ref type[] data) and new worker(type[] data) then private weak type[] data; in its properties.
- Concurrently writing to a different items of fixed-size array seems to be fine.
- Breaking tasks into packets may improve speed, however its inefficient if some packets finish way before the others. Assess packet numbers/sizes on a case-by-case basis.
- Setting max_threads to -1 causes considerable delays when processing a large number of tasks, use GLib.get_num_processors() instead.
In various tests, Waiting for threads to complete was best handled by checking the last item in a verification checklist (int[]) set to the packet size, where each packet checks-off its entry in the array when its done.- The above was a dumb mistake, checking needs to be done using a packetcomplete int, incremented with the aid of mutex.
- threadpool.unprocessed() returns the number of tasks yet to be sent to the threadpool, not the number of incomplete tasks.
- threadpool.get_num_threads() was not a reliable measure of currently running threads.
#+RESULTS:
TRUNCATE:vala:
Truncate a string
#+RESULTS:
UNDO:vala:
Simple undo test using a function arg buffer.
Buffer grows as required, up to a cap, then re-uses positions.
#+RESULTS:
UINT:vala:
Check behavior of uint here.
Notes:
- uint can be used to clearly define a variable shouldn't be negative, hovever:
- casting a negaitve int to uint will wrap it around to a huge number
- subtracting two uints to negative will also wrap it
- wrapped numbers can't be checked for an invalid negative number with u > -1
Conclusion: don't use uint unless you need to store a number from 2 to 4 billion without going 64-bit, or unless some other function requires/generates it, eg string.hash().
#+RESULTS:
UNICHAR2:vala:
#+RESULTS:
UNICHAR:vala:
#+RESULTS:
UNIQUENAME:vala:
#+RESULTS:
WRITEFILE:vala:
#+RESULTS:
WHIGGLE:vala:
beekaus iqlic is y laqwidj of kaeos...
#+RESULTS:
XFORMRC:vala:
Transform sequential columns into sequential rows, with gaps in the data...
#+RESULTS:
TBLFM ELISP:org:
Test common Elisp functions in org tblfm formulae
upcase
Convert text to uppercase
| ! | ITEM | UP | |---+-------+-------| | 1 | green | GREEN | | 2 | blue | BLUE | | 3 | red | RED | #+TBLFM: @2$3..@4$3='(upcase $2)
downcase
convert text to lowercase
| ! | ITEM | DOWN | |---+-------+-------| | 1 | GREEN | green | | 2 | BLUE | blue | | 3 | RED | red | #+TBLFM: @2$3..@4$3='(downcase $2)
format
format text using tags
| ! | ITEM | COST | FORMAT | |---+-------+------+---------| | 1 | GREEN | 30 | EUR €30 | | 2 | BLUE | 10 | EUR €10 | | 3 | RED | 18 | EUR €18 | #+TBLFM: @2$4..@4$4='(format "EUR €%d" (string-to-number $3))
concat
Combine strings
| ! | ITEM | CONCAT | |---+-------+------------| | 1 | GREEN | RGBA_GREEN | | 2 | BLUE | RGBA_BLUE | | 3 | RED | RGBA_RED | #+TBLFM: @2$3..@4$3='(concat "RGBA_" $2)
make-string
Create a string of n characters
Args are:
Args are:
- make-string command
- number of characters
- character to use, prefixed with a question-mark
- switch for ascii/unicode, 0 or 1
| ! | ITEM | QTY | PLOT | |---+-------+-----+----------| | 1 | GREEN | 2 | ██ | | 2 | BLUE | 6 | ██████ | | 3 | RED | 8 | ████████ | #+TBLFM: @2$4..@4$4='(make-string (string-to-number $3) ?█ 1)
substring
Extract part of a string
Args are:
Negative length denotes maximum length - n, after start
Args are:
- substring command
- string to extract a substring from
- start index of substring
- length of string to extract, after start
Negative length denotes maximum length - n, after start
| ! | ITEM | SUBSTR | -S | -L | -S-L | |---+-----------+--------+------+-------+------| | 1 | GREENISHY | GRE | ISHY | GREEN | ISH | | 2 | BLUEISHY | BLU | ISHY | BLUE | ISH | | 3 | REDISHY | RED | ISHY | RED | ISH | #+TBLFM: @2$3..@4$3='(substring $2 0 3) :: @2$4..@4$4='(substring $2 -4 nil) :: @2$5..@4$5='(substring $2 0 -4) :: @2$6..@4$6='(substring $2 -4 -1)
string
Create a string from characters
Each character must be prefixed with a question-mark.
Each character must be prefixed with a question-mark.
| ! | ITEM | STRING | |---+-------+--------| | 1 | GREEN | COLOR | | 2 | BLUE | COLOR | | 3 | RED | COLOR | #+TBLFM: @2$3..@4$3='(string ?C ?O ?L ?O ?R)
abs
Absolute value of a number
| ! | A | B | ABS | |---+----+----+-----| | 1 | 2 | 30 | 60 | | 2 | -6 | 10 | 60 | | 3 | 8 | 18 | 144 | #+TBLFM: @2$4..@4$4='(abs (* (string-to-number $2) (string-to-number $3)))
mod
Modulo
| ! | A | B | MOD | |---+-----+----+-----| | 1 | 203 | 30 | 23 | | 2 | 612 | 10 | 2 | | 3 | 800 | 18 | 8 | #+TBLFM: @2$4..@4$4='(mod (string-to-number $2) (string-to-number $3))
random
Generate a random number
Numeric arg is the upper limit, from 0.
Numeric arg is the upper limit, from 0.
| ! | A | B | RAND | |---+---+----+------| | 1 | 2 | 30 | 28 | | 2 | 6 | 10 | 6 | | 3 | 8 | 18 | 15 | #+TBLFM: @2$4..@4$4='(random (string-to-number $3))
celing
Round a number up
| ! | A | B | CEIL | |---+---+------+------| | 1 | 2 | 30.8 | 31 | | 2 | 6 | 10.1 | 11 | | 3 | 8 | 18.4 | 19 | #+TBLFM: @2$4..@4$4='(ceiling (string-to-number $3))
floor
Round a number down, towards negative infinity.
| ! | A | B | FLOOR | |---+---+-------+-------| | 1 | 2 | 30.8 | 30 | | 2 | 6 | 10.1 | 10 | | 3 | 8 | -18.4 | -19 | #+TBLFM: @2$4..@4$4='(floor (string-to-number $3))
round
Round a number to the nearest integer.
| ! | A | B | ROUND | |---+---+-------+-------| | 1 | 2 | 30.8 | 31 | | 2 | 6 | 10.1 | 10 | | 3 | 8 | -18.4 | -18 | #+TBLFM: @2$4..@4$4='(round (string-to-number $3))
truncate
Similar to floor, however truncates towards zero.
| ! | A | B | TRUNC | |---+---+-------+-------| | 1 | 2 | 30.8 | 30 | | 2 | 6 | 10.1 | 10 | | 3 | 8 | -18.4 | -18 | #+TBLFM: @2$4..@4$4='(truncate (string-to-number $3))
min
Minimum of two numbers
| ! | A | B | MIN | |---+----+------+------| | 1 | 2 | 30 | 2 | | 2 | 60 | 10.1 | 10.1 | | 3 | -8 | -9 | -9 | #+TBLFM: @2$4..@4$4='(min (string-to-number $2) (string-to-number $3))
max
Maximum of two numbers
| ! | A | B | MAX | |---+----+------+-----| | 1 | 2 | 30 | 30 | | 2 | 60 | 10.1 | 60 | | 3 | -8 | -9 | -8 | #+TBLFM: @2$4..@4$4='(max (string-to-number $2) (string-to-number $3))
sqrt
Square root of A.
| ! | A | SQRT | |---+-----+--------------------| | 1 | 2.2 | 1.4832396974191326 | | 2 | 0.5 | 0.7071067811865476 | | 3 | 1.5 | 1.224744871391589 | #+TBLFM: @2$3..@4$3='(sqrt (string-to-number $2))
expt
A to the power of B.
Use with caution.
Use with caution.
| ! | A | B | EXPT | |---+----+-----+------------------------| | 1 | 2 | -30 | 9.313225746154785e-10 | | 2 | 60 | -10 | 1.6538171687920202e-18 | | 3 | 8 | -9 | 7.450580596923828e-09 | #+TBLFM: @2$4..@4$4='(expt (string-to-number $2) (string-to-number $3))
exp
A to the power of e.
| ! | A | EXP | |---+-----+--------------------| | 1 | 2.2 | 9.025013499434122 | | 2 | 0.5 | 1.6487212707001282 | | 3 | 1.5 | 4.4816890703380645 | #+TBLFM: @2$3..@4$3='(exp (string-to-number $2))
log
Logarithm of A, with a base of B, or e if the base isn't specified.
Use with caution.
Use with caution.
| ! | A | B | LOG | |---+-----+------+---------------------| | 1 | 2.2 | 5.0 | 0.48989610240497816 | | 2 | 0.5 | 10.0 | -0.3010299956639812 | | 3 | 1.5 | 6.0 | 0.22629438553091683 | #+TBLFM: @2$4..@4$4='(log (string-to-number $2) (string-to-number $3))
asin
Arc sine of A.
| r | A | SIN | | | |----+-------+---------+----------------------+----------------------| | 2 | -2.00 | nan | | | | 3 | -1.80 | nan | | | | 4 | -1.60 | nan | | | | 5 | -1.40 | nan | | | | 6 | -1.20 | nan | | | | 7 | -1.00 | -1.5708 | ████████████████████ | | | 8 | -0.80 | -0.9273 | ████████████ | | | 9 | -0.60 | -0.6435 | ████████ | | | 10 | -0.40 | -0.4115 | ██████ | | | 11 | -0.20 | -0.2014 | ███ | | | 12 | 0.00 | 0.0000 | | | | 13 | 0.20 | 0.2014 | | ███ | | 14 | 0.40 | 0.4115 | | ██████ | | 15 | 0.60 | 0.6435 | | ████████ | | 16 | 0.80 | 0.9273 | | ████████████ | | 17 | 1.00 | 1.5708 | | ████████████████████ | | 18 | 1.20 | nan | | | | 19 | 1.40 | nan | | | | 20 | 1.60 | nan | | | | 21 | 1.80 | nan | | | | 22 | 2.00 | nan | | | #+TBLFM: @2$2..@22$2=((($1-1.9999)-10.0)/5.0);%.2f :: @2$3..@22$3='(asin (string-to-number $2));%.4f :: $4='(orgtbl-uc-draw-cont $3 0.0 -1.6 20) :: $5='(orgtbl-uc-draw-cont $3 0.0 1.6 20)
acos
Arc cosine of A.
| r | A | SIN | | | |----+-------+--------+-----+----------------------| | 2 | -2.00 | nan | | | | 3 | -1.80 | nan | | | | 4 | -1.60 | nan | | | | 5 | -1.40 | nan | | | | 6 | -1.20 | nan | | | | 7 | -1.00 | 3.1416 | | ████████████████████ | | 8 | -0.80 | 2.4981 | | ████████████████ | | 9 | -0.60 | 2.2143 | | ██████████████ | | 10 | -0.40 | 1.9823 | | █████████████ | | 11 | -0.20 | 1.7722 | | ████████████ | | 12 | 0.00 | 1.5708 | | ██████████ | | 13 | 0.20 | 1.3694 | | █████████ | | 14 | 0.40 | 1.1593 | | ████████ | | 15 | 0.60 | 0.9273 | | ██████ | | 16 | 0.80 | 0.6435 | | ████ | | 17 | 1.00 | 0.0000 | | | | 18 | 1.20 | nan | | | | 19 | 1.40 | nan | | | | 20 | 1.60 | nan | | | | 21 | 1.80 | nan | | | | 22 | 2.00 | nan | | | #+TBLFM: @2$2..@22$2=((($1-1.9999)-10.0)/5.0);%.2f :: @2$3..@22$3='(acos (string-to-number $2));%.4f :: $4='(orgtbl-uc-draw-cont $3 0.0 -1.6 20) :: $5='(orgtbl-uc-draw-cont $3 0.0 3.1416 20)
atan
Arc tangent of A.
| r | A | SIN | | | |----+-------+---------+----------------+----------------| | 2 | -2.00 | -1.1071 | ██████████████ | | | 3 | -1.80 | -1.0637 | ██████████████ | | | 4 | -1.60 | -1.0122 | █████████████ | | | 5 | -1.40 | -0.9505 | ████████████ | | | 6 | -1.20 | -0.8761 | ███████████ | | | 7 | -1.00 | -0.7854 | ██████████ | | | 8 | -0.80 | -0.6747 | █████████ | | | 9 | -0.60 | -0.5404 | ███████ | | | 10 | -0.40 | -0.3805 | █████ | | | 11 | -0.20 | -0.1974 | ███ | | | 12 | 0.00 | 0.0000 | | | | 13 | 0.20 | 0.1974 | | ███ | | 14 | 0.40 | 0.3805 | | █████ | | 15 | 0.60 | 0.5404 | | ███████ | | 16 | 0.80 | 0.6747 | | █████████ | | 17 | 1.00 | 0.7854 | | ██████████ | | 18 | 1.20 | 0.8761 | | ███████████ | | 19 | 1.40 | 0.9505 | | ████████████ | | 20 | 1.60 | 1.0122 | | █████████████ | | 21 | 1.80 | 1.0637 | | ██████████████ | | 22 | 2.00 | 1.1071 | | ██████████████ | #+TBLFM: @2$2..@22$2=((($1-1.9999)-10.0)/5.0);%.2f :: @2$3..@22$3='(atan (string-to-number $2));%.4f :: $4='(orgtbl-uc-draw-cont $3 0.0 -1.6 20) :: $5='(orgtbl-uc-draw-cont $3 0.0 1.6 20)
sin
Sine of A.
| r | A | SIN | | | |----+-------+---------+---------------+---------------| | 2 | -2.00 | -0.9093 | ████████████ | | | 3 | -1.80 | -0.9738 | █████████████ | | | 4 | -1.60 | -0.9996 | █████████████ | | | 5 | -1.40 | -0.9854 | █████████████ | | | 6 | -1.20 | -0.9320 | ████████████ | | | 7 | -1.00 | -0.8415 | ███████████ | | | 8 | -0.80 | -0.7174 | █████████ | | | 9 | -0.60 | -0.5646 | ███████ | | | 10 | -0.40 | -0.3894 | █████ | | | 11 | -0.20 | -0.1987 | ███ | | | 12 | 0.00 | 0.0000 | | | | 13 | 0.20 | 0.1987 | | ███ | | 14 | 0.40 | 0.3894 | | █████ | | 15 | 0.60 | 0.5646 | | ███████ | | 16 | 0.80 | 0.7174 | | █████████ | | 17 | 1.00 | 0.8415 | | ███████████ | | 18 | 1.20 | 0.9320 | | ████████████ | | 19 | 1.40 | 0.9854 | | █████████████ | | 20 | 1.60 | 0.9996 | | █████████████ | | 21 | 1.80 | 0.9738 | | █████████████ | | 22 | 2.00 | 0.9093 | | ████████████ | #+TBLFM: @2$2..@22$2=((($1-1.9999)-10.0)/5.0);%.2f :: @2$3..@22$3='(sin (string-to-number $2));%.4f :: $4='(orgtbl-uc-draw-cont $3 0.0 -1.6 20) :: $5='(orgtbl-uc-draw-cont $3 0.0 1.6 20)
cos
Cosine of A
| r | A | SIN | | | |----+-------+---------+--------+---------------| | 2 | -2.00 | -0.4161 | ██████ | | | 3 | -1.80 | -0.2272 | ███ | | | 4 | -1.60 | -0.0292 | █ | | | 5 | -1.40 | 0.1700 | | ███ | | 6 | -1.20 | 0.3624 | | █████ | | 7 | -1.00 | 0.5403 | | ███████ | | 8 | -0.80 | 0.6967 | | █████████ | | 9 | -0.60 | 0.8253 | | ███████████ | | 10 | -0.40 | 0.9211 | | ████████████ | | 11 | -0.20 | 0.9801 | | █████████████ | | 12 | 0.00 | 1.0000 | | █████████████ | | 13 | 0.20 | 0.9801 | | █████████████ | | 14 | 0.40 | 0.9211 | | ████████████ | | 15 | 0.60 | 0.8253 | | ███████████ | | 16 | 0.80 | 0.6967 | | █████████ | | 17 | 1.00 | 0.5403 | | ███████ | | 18 | 1.20 | 0.3624 | | █████ | | 19 | 1.40 | 0.1700 | | ███ | | 20 | 1.60 | -0.0292 | █ | | | 21 | 1.80 | -0.2272 | ███ | | | 22 | 2.00 | -0.4161 | ██████ | | #+TBLFM: @2$2..@22$2=((($1-1.9999)-10.0)/5.0);%.2f :: @2$3..@22$3='(cos (string-to-number $2));%.4f :: $4='(orgtbl-uc-draw-cont $3 0.0 -1.6 20) :: $5='(orgtbl-uc-draw-cont $3 0.0 1.6 20)
tan
Tangent of A
| r | A | SIN | | | |----+-------+----------+----------------------+----------------------| | 2 | -2.00 | 2.1850 | | | | 3 | -1.80 | 4.2863 | | | | 4 | -1.60 | 34.2325 | | | | 5 | -1.40 | -5.7979 | | | | 6 | -1.20 | -2.5722 | | | | 7 | -1.00 | -1.5574 | ████████████████████ | | | 8 | -0.80 | -1.0296 | █████████████ | | | 9 | -0.60 | -0.6841 | █████████ | | | 10 | -0.40 | -0.4228 | ██████ | | | 11 | -0.20 | -0.2027 | ███ | | | 12 | 0.00 | 0.0000 | | | | 13 | 0.20 | 0.2027 | | ███ | | 14 | 0.40 | 0.4228 | | ██████ | | 15 | 0.60 | 0.6841 | | █████████ | | 16 | 0.80 | 1.0296 | | █████████████ | | 17 | 1.00 | 1.5574 | | ████████████████████ | | 18 | 1.20 | 2.5722 | | | | 19 | 1.40 | 5.7979 | | | | 20 | 1.60 | -34.2325 | | | | 21 | 1.80 | -4.2863 | | | | 22 | 2.00 | -2.1850 | | | #+TBLFM: @2$2..@22$2=((($1-1.9999)-10.0)/5.0);%.2f :: @2$3..@22$3='(tan (string-to-number $2));%.4f :: $4='(orgtbl-uc-draw-cont $3 0.0 -1.6 20) :: $5='(orgtbl-uc-draw-cont $3 0.0 1.6 20)
float-pi
PI
| ! | A | PI | |---+------+------| | 1 | 1.0 | 3.14 | | 2 | 10.0 | 3.14 | | 3 | 20.0 | 3.14 | #+TBLFM: @2$3..@4$3='(eval float-pi);%.2f
float-e
e
| ! | A | e | |---+------+------| | 1 | 1.0 | 2.72 | | 2 | 10.0 | 2.72 | | 3 | 20.0 | 2.72 | #+TBLFM: @2$3..@4$3='(eval float-e);%.2f
HEXTILE:hou::vex:
Hextile gradient inline vex (COPs).
Derivative work of various sources, most helpful was Procedural Graphics Tutorial: Hexagon Effects by Andrew Hung.
Used as a transition input for another effect.
SDFBOXMASK:hou::vex:
Rectangular sdf mask inline vex (COPs).
This is a vex translation of a polygon shader by Inigo Quilez here.
Used for masking with rounded corners.
GTKICONS:gtk4::vala:
TBLFM PARSER:vala:
#+RESULTS:
ORGNQQ:rebol3:
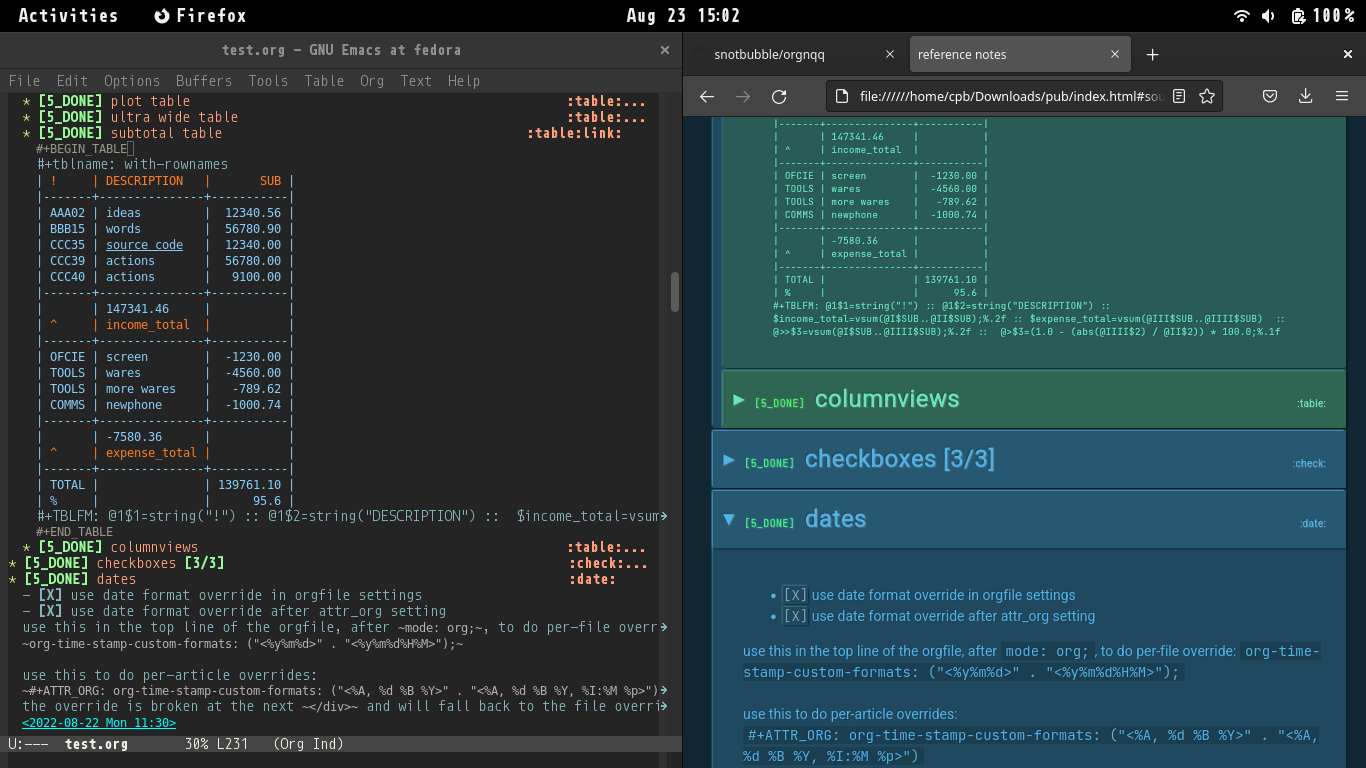
gifded queue to export an orgfile to html.
Used to make this site.
Mostly written in Rebol3, a beutiful low-effort high-payoff language... reminds me of Python before the crowds...
The queue:
Used to make this site.
Mostly written in Rebol3, a beutiful low-effort high-payoff language... reminds me of Python before the crowds...
The queue:
preflight
shellscript node to clear out pub dirs
loader
hardcoded vala node to load a file
org title:rebol3:
org headlines:rebol3:
org tables:rebol3:
org source:rebol3:
org checkboxes:rebol3:
org lists:rebol3:
org properties:rebol3:
org dates:rebol3:
org links:rebol3:
org style:rebol3:
org include:rebol3:
insert script
html node that simply replaces <!--[lastres]--> with the incoming text
prepend css
html node that simply replaces <!--[lastres]--> with the incoming text
save fonts:rebol3:
save html
Hardcoded Vala node that saves the incoming text to index file
publish
shellscript node to copy everything to a publish location
ORG SBE:org:
#+RESULTS:
: 1.62760416666667
| ITEM | VAL | XCH | ATAX | AUD | |-------+------+------+------+-------| | AUD | 88.0 | 1.0 | 0.76 | 66.9 | | EUR | 60.0 | 1.63 | 0.52 | 50.9 | |-------+------+------+------+-------| | TOTAL | | | | 117.8 | #+TBLFM: @3$3='(org-sbe "x");%.2f :: $5=(($2*$3)*$4);%.1f :: @>$5=vsum(@I$5..@II$5);%.1f
DOTEMACS:el:
REBOLMODE:el:
Rebol3 for orgmode src blocks.
rebol3-mode.el
#+RESULTS:
ob-rebol3.el
#+RESULTS:
VALAMODE:el:
Vala for orgmode src blocks
vala_mode.el
Only includes keywords I usually see.
Brace matching detects commented braces.
#+RESULTS:
ob-vala.el
Bare-minimum bridge to valac.
This will attempt to:
- Save the src block code to a temp vala file
- Compile the temp vala file using src block flags
- Delete the temp vala file, so it could fuck-up and delete some other file
- Run the resulting binary ./valatemp
#+RESULTS:
FORCEUTF8:el:
Used for testing unicode, and dealing with a newline issue.
QUOTELINE:el:
Wrap text on the current line in double-quotes.
MOVELINE:el:
Derivative work, edited to keep cursor x pos
HIGHLIGHTWORD:el:
Derivative work, minor edit.
THE TAB KEY IS FOR TAB:el:
JFC this is getting old...
R3 RENAME:rebol3:
Batch rename with Rebol3.
sample name...: "Within Destruction - Lotus - 11 P.O.P..flac"
desired output: "within_destruction_lotus_11_pop.flac"
the crude way:
;; rename test
;; by c.p.brown 2023
f: read %./*.flac
foreach x f [
n: lowercase (to-string x)
replace n ".flac" ""
n: reword/escape n [ " " "_" "." "" "-" "" "(" "" ")" "" ] none
replace/all n "__" "_"
n: join n ".flac"
call compose [ "cp" (to-string x) (n) ]
]
the more reliable way, no duplicate underscores:
;; rename test using parse
;; by c.p.brown 2023
f: read %./*.flac
nup: charset ".-()"
foreach x f [
n: lowercase to-string x
parse n [
a: any [ [ not ".flac" ] remove nup | skip ]
:a any [ remove some #" " insert "_" | skip ]
]
print [ "renaming from:" x "^/ to:" n "^/"]
t: open/new/write to-file n
write/binary t read/binary x
]
another test:
"Within Destruction - Lotus - (.- )- 11 P.O.P..flac"
output:
"within_destruction_lotus_11_pop.flac"
sample name...: "Within Destruction - Lotus - 11 P.O.P..flac"
desired output: "within_destruction_lotus_11_pop.flac"
the crude way:
the more reliable way, no duplicate underscores:
another test:
"Within Destruction - Lotus - (.- )- 11 P.O.P..flac"
output:
"within_destruction_lotus_11_pop.flac"
LYNX CRAWL:cmd:
then convert to a xml:
wrap each line in <url><loc> ... <loc><url>
insert a header:
then append </urlset>
and save as sitemap.xml
FIREJAIL FIREFOX:cmd:
It won't take at first, so run the above command before loading firefox, open and close firefox, run the command again, wait a few seconds, run it a third time... then it should be firejailed. Check by looking at:
You should only see folders that firefox needs to use.
DUI:gtk3::red:
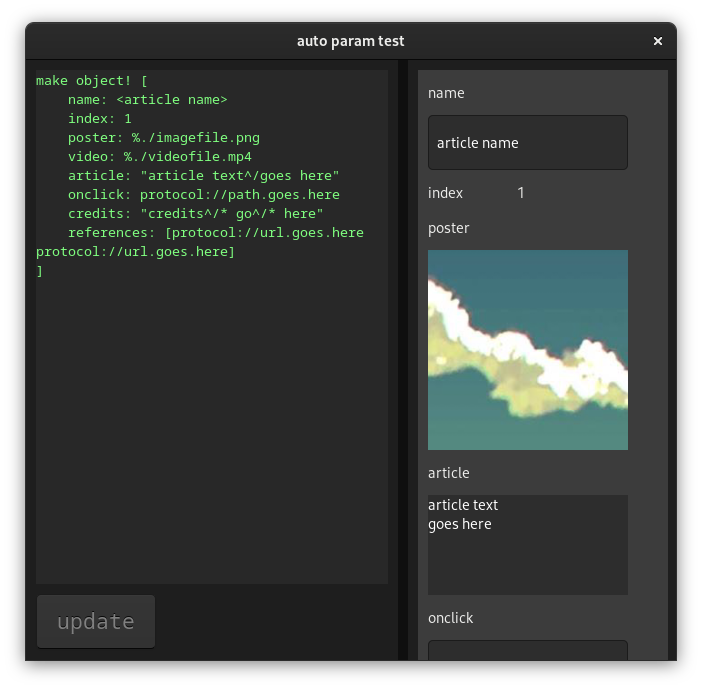
Dynamic ui test.
Creates fields/labels from items in a data structure.
Here for reference only. I've since moved from Red to Vala.
Red [ needs 'view ]
;; tag used for single line strings (fields), thanks to Boleslav Březovský re: "string" vs {string}
recycle/off
articledata: context[
thisis: 'articledata
name: <article name>
index: 1 ;; used for sorting
poster: %./imagefile.png
video: %./videofile.mp4
article: {article text^/goes here}
onclick: protocol://path.goes.here
credits: {credits^/* go^/* here}
references: [ protocol://url.goes.here protocol://url.goes.here ]
]
getext: func [ f ] [ last split to-string f "." ]
makeparams: func [ d ] [
k: d/thisis
w: words-of d
v: values-of d
i: 1
n: copy []
append n [ below ]
foreach p w [
switch mold type? v/:i [
"integer!" [ append n compose/deep [ across text (to-string p) text (to-string v/(i)) return below ] ]
"tag!" [
append n compose/deep [
text (to-string p) field 200x55 with [ text: (to-string v/(i)) ] on-change [
(to-set-path compose [ (k) (p) ]) to-tag face/text src/text: (quote mold ) (k)
]
] probe n
]
"string!" [
append n compose/deep [
text (to-string p) area 200x100 with [ text: (to-string v/(i)) ] on-change [
(to-set-path compose [ (k) (p) ]) face/text src/text: (quote mold ) (k)
]
]
]
"url!" [
append n compose/deep [
text (to-string p) field 200x55 with [ text: (to-string v/(i)) ] on-change [
(to-set-path compose [ (k) (p) ]) to-url face/text src/text: (quote mold ) (k)
]
]
]
"block!" [
append n compose/deep [
text (to-string p) text-list 200x100 data [(v/(i))] on-change [
(to-set-path compose [ (k) (p) ]) face/data src/text: (quote mold ) (k)
]
]
]
"file!" [
either (getext v/:i) = "png" [
append n compose/deep [
text (to-string p) image 200x200 with [ image: load (v/(i)) ] on-up [
img: request-file/filter ["pics" "*.png"]
unless none? img [
img: to-file rejoin [ "./" second split-path img ]
if exists? img [
face/image: load img
unless none? face/image [
(to-set-path compose [ (k) (p) ]) img src/text: (quote mold ) (k)
]
]
]
]
]
] [ print [ "file not a png, skipping..." ] ]
]
]
i: i + 1
]
n
]
nudgev: func [ ] [
aa/offset/x: 0
pp/offset/y: 0
vv/offset/y: 0
aa/offset/y: 0
bb/offset/y: 0
aa/size/x: vv/offset/x
src/size/x: aa/size/x - 20
bb/offset/x: vv/offset/x + vv/size/x
bb/size/x: pp/size/x - (vv/offset/x + vv/size/x)
cc/size/x: bb/size/x - 70
]
view/tight/flags/options [
title "auto param test"
pp: panel 650x600 255.0.0 [
aa: panel 300x600 30.30.30 [
below
src: area 300x510 40.40.40 font-name "consolas" font-size 10 font-color 128.255.128
doit: button 120x55 30.30.30 "update" font-name "consolas" font-size 16 font-color 128.128.128 [
tmp: do [ reduce load src/text ]
articledata: reduce copy tmp/1
src/text: (mold articledata)
clear cc/pane
append cc/pane layout/only makeparams articledata
]
]
vv: panel 10x600 15.15.15 loose on-drag [ nudgev ]
bb: panel 300x600 30.30.30 [
cc: panel 300x1000 60.60.60 loose [ ] on-drag [
face/offset/x: 10 face/offset/y: min face/offset/y 10
] on-wheel [
either event/picked > 0 [ face/offset/y: face/offset/y + 40 ] [ face/offset/y: face/offset/y - 40 ]
bo: (bb/size/y - face/size/y) - 100
bo: min bo 0
face/offset/y: max bo min face/offset/y 10
]
]
]
do [
aa/offset/x: 0
append cc/pane layout/only makeparams articledata
src/text: (mold articledata)
nudgev
]
] [ resize ] [
actors: object [
on-resizing: function [ face event ] [
if face/size/x > 500 [
if face/size/y > 300 [
pp/size: face/size
vv/size/y: face/size/y
aa/size/y: face/size/y
bb/size/y: face/size/y
vv/offset/x: face/size/x - (bb/size/x + vv/size/x)
doit/offset/y: face/size/y - (doit/size/y + 100)
src/size/y: doit/offset/y - 20
nudgev
]
]
]
]
]
Creates fields/labels from items in a data structure.
Here for reference only. I've since moved from Red to Vala.
PIC
E72:pic::glsl::demo:
SDF fragment shader
Besides the watermark, this image is sdf math, including text decals, shader is here
It is not optimized; there is no bvh. It will cook your device, crash your display driver and log you out... view at your own risk.
Relies heavily on examples published by:
Prototyped on cpu in Houdini Vex for safety, before finishing it off in KodeLife.
Render above is from the vex version, as its trivial to output an image sequence from Houdini.
Conclusion to this test: AA kills it. Running it on client hardware too risky. Try again later with WebGPU+Vulkan...
Not made for Bahco. Chosen as its a simple product to model, has text and movable parts, had the measurements on-hand.
Besides the watermark, this image is sdf math, including text decals, shader is here
It is not optimized; there is no bvh. It will cook your device, crash your display driver and log you out... view at your own risk.
Relies heavily on examples published by:
- Inigo Quilez
- Jamie Wong
Prototyped on cpu in Houdini Vex for safety, before finishing it off in KodeLife.
Render above is from the vex version, as its trivial to output an image sequence from Houdini.
Conclusion to this test: AA kills it. Running it on client hardware too risky. Try again later with WebGPU+Vulkan...
Not made for Bahco. Chosen as its a simple product to model, has text and movable parts, had the measurements on-hand.